DNA
DNA4mC-LIP: a linear integration method to identify N4-methylcytosine site in multiple species
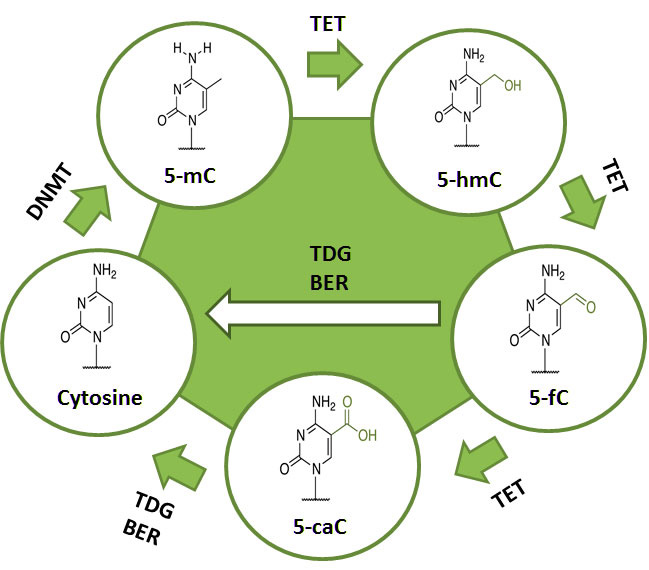 |
DNA methylation is an epigenetic mechanism that occurs by the addition of a methyl (CH3) group to DNA, thereby often modifying the function of the genes and affecting gene expression. The 6-methyladenone (6mA), 5-methylcytosine (5mC) and 4-methylcytosine (4mC) are three most common and major modification observed in both prokaryotic and eukaryotic genomes However, compared with 6mA and 5mC, our knowledge about the functions of 4mC modification is still far from sufficient. Effective and accurate identification of 4mC sites will be helpful to reveal its biological functions and mechanisms. DNA4mC-LIP, a linear integration method by combining existing predictors identify 4mC sites in multiple species. The results obtained from independent dataset demonstrated that DNA4mC-LIP outperformed existing methods for identifying 4mC sites. |
iNuc-PhysChem: Identification of nucleosomes in S. cerevisiae genome
 |
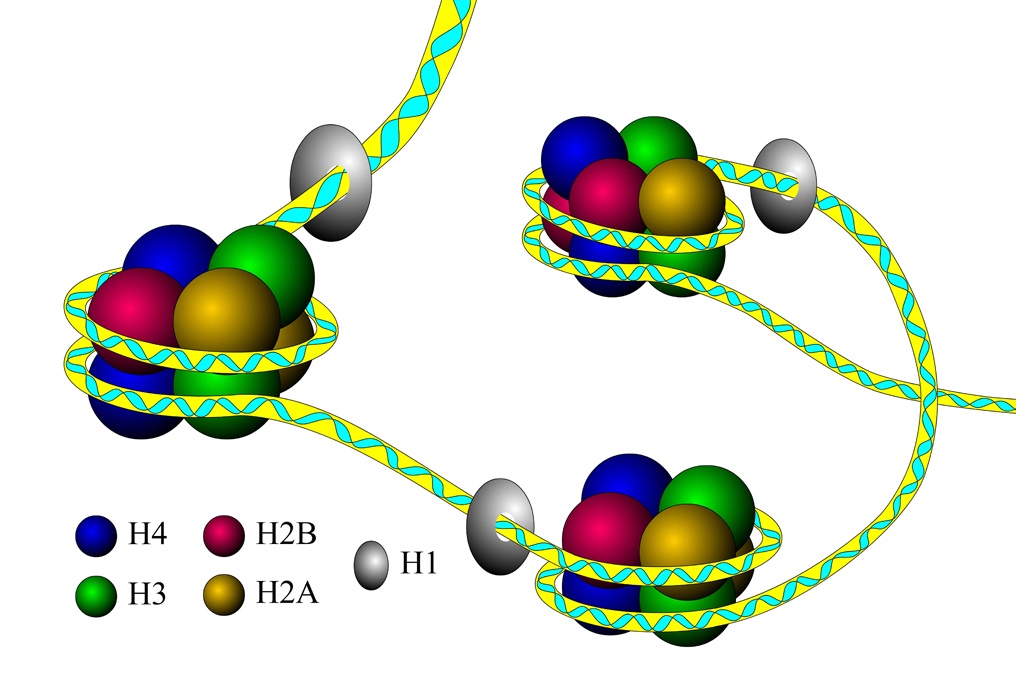
Nucleosome positioning has important roles in key cellular processes. Although intensive efforts have been made in this area, the rules defining nucleosome positioning is still elusive and debated. In this study, we carried out a systematic comparison among the profiles of twelve DNA physicochemical features between the nucleosomal and linker sequences in the Saccharomyces cerevisiae genome. We found that nucleosomal sequences have some position-specific physicochemical features, which can be used for in-depth studying nucleosomes. Meanwhile, a new predictor, called iNuc-PhysChem, was developed for identification of nucleosomal sequences by incorporating these physicochemical properties into a 1788-D (dimensional) feature vector, which was further reduced to a 884-D vector via the IFS (incremental feature selection) procedure to optimize the feature set. It was observed by a cross-validation test on a benchmark dataset that the overall success rate achieved by iNuc-PhysChem was over 96% in identifying nucleosomal or linker sequences. |
iRSpot-PseDNC
,
iRSpot-Pse6NC
and
iRSpot-Pse6NC2.0
: Prediction of recombination spots in S. cerevisiae genome
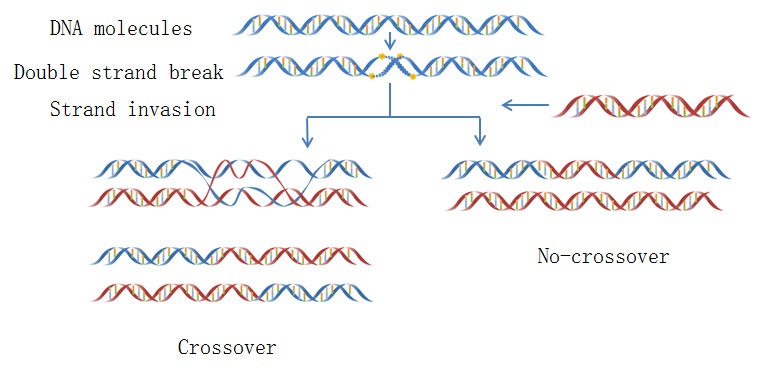 |
Meiotic recombination is one of the most important driving forces in the process of biological evolution, which is initiated by double-stand DNA breaks (DSBs). Recombination has important roles in genome diversity and evolution. Based on dataset containing both ORF and non-ORF recombination sites, we construct a predictor called ‘iRSpot-Pse6NC2.0’ using SVM classifier by incorporating the key hexamer features into the general PseKNC (Pseudo K-tuple Nucleotide Composition) via the binomial distribution feature selection approach. The 5-fold cross-validated results showed that the maximum overall accuracy of 77.61%. |
iNuc-PseKNC: APredicting nucleosomes in H. sapiens, C. elegan, D. melanogaster genomes
 |
The web-server iNuc-PseKNC was developed to predict nucleosome occupancy of H. sapiens, C. elegan and D. melanogaster . The overall accuracy of 86.27%, 86.90%, 79.97% were achieved respectively for the above spieces by using jackknife cross-validation. The results obtained by iNuc-PseKNC on various benchmark datasets used by the previous investigators for different genomes also indicated that the current predictor remarkably outperformed its counterparts. |
iTIS-PseTNC: Identification of translation initiation site in human genes
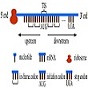 |
The web-server iTIS-PseTNC was developed to identify Translation initiation site (TIS) by using the physicochemical properties of the pseudo trinucleotide composition. It was observed by the rigorous cross-validation test on the benchmark dataset that the overall success rate achieved by the new predictor in identifying TIS was over 97%. |
iPro54-PseKNC
and
iPro70-PseZNC
: Identification of sigma54 and sigma70 promoter in prokaryotic genomes
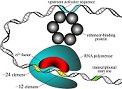 |
Promoter is a region of DNA that determines the transcription of a particular gene. In prokaryotes, it is the sigma factors of RNA holoenzyme that recognize and bind to the promoter sequences during gene transcription. The sigma-54 promoters are unique in prokaryotic genome and responsible for transcripting carbon and nitrogen-related genes. With the avalanche of genome sequences generated in the postgenomic age, it is highly desired to develop automated methods for rapidly and effectively identifying the sigma-54 promoters. Here, a predictor called ‘iPro54-PseKNC’ was developed. In the predictor, the samples of DNA sequences were formulated by a novel feature vector called ‘pseudo k-tuple nucleotide composition’, which was further optimized by the incremental feature selection procedure. The performance of iPro54-PseKNC was examined by the rigorous jackknife cross-validation tests on a stringent benchmark data set. |
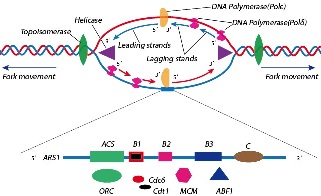 |
The initiation of replication origin is an extremely important process of DNA replication. The distribution of replication origin regions (ORIs) is the major determinant of the timing of genome replication. Thus, correctly identifying ORIs is crucial to understand DNA replication mechanism. With the avalanche of genome sequences generated in the post-genomic age, it is highly desired to develop computational methods for rapidly, effectively and automatically identifying the ORIs in genome. In this paper,we developed a predictor called iORI-PseKNC for identifying ORIs in Saccharomyces cerevisiae genome. In the predictor, based on the concept of the global and long-range sequence-order effects of DNA sequence, the feature called “pseudo k-tuple nucleotide composition” (PseKNC) was used to encode the DNA sequences by incorporating six local structural properties of 16 dinucleotides. The overall success rate of 83.72% was achieved from the jackknife cross-validation test on an objective benchmark dataset. |
iTerm-PseKNC: Identifying bacterial terminators
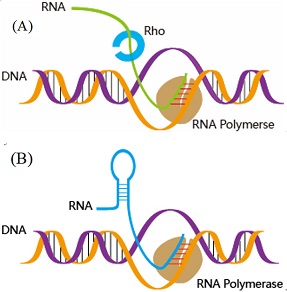 |
iTerm-PseKNC is a webserver for the identification of bacterial transcriptional terminators based on machine learning method. In the predictor, 5-tuple nucletide frequency and physicochemical property were extracted to formulate samples. The binomial distribution technique was proposed to rank 1024 5-tuple nucleotides. Then the incremental feature selection (IFS) was used to determine the optimal features which could produce the maximum accuracy. The support vector machine (SVM) was utilized to perform prediction. Five-fold cross-validated results showed that 86.78% terminators and 99.99% non-terminators can be correctly recognized, respectively, suggesting that our proposed model is very powerful. This study provides a new strategy to identify terminators. We hope the webserver could provide convenience for Biochemistry scholars. |
iDNA4mC: identifying DNA 4-methylcytosine sites
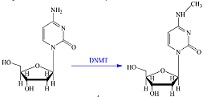 |
DNA N4-methylcytosine (4mC) is an epigenetic modification. The knowledge about the distribution of 4mC is helpful for understanding its biological functions. Although experimental methods have been proposed to detect 4mC sites, they are expensive for performing genome-wide detections. Thus, it is necessary to develop computational methods for predicting 4mC sites. We developed iDNA4mC, the first webserver to identify 4mC sites, in which DNA sequences are encoded with both nucleotide chemical properties and nucleotide frequency. The predictive results of the rigorous jackknife test and cross species test demonstrated that the performance of iDNA4mC is quite promising and holds high potential to become a useful tool for identifying 4mC sites. |
iDNA6mA-PseKNC
and
i6mA-Pred
:Identifying DNA N6-methyladenosine sites
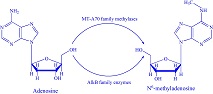 |
The web-server was developed to identify DNA N6-methyladenine (6mA) sites in the rice gemome. The results of jackknife test based on the benchmark dataset indicates that the current predictor may become a useful high-throughput tool in identifying 6mA sites. |
PseKNC
and
PseKNC-General
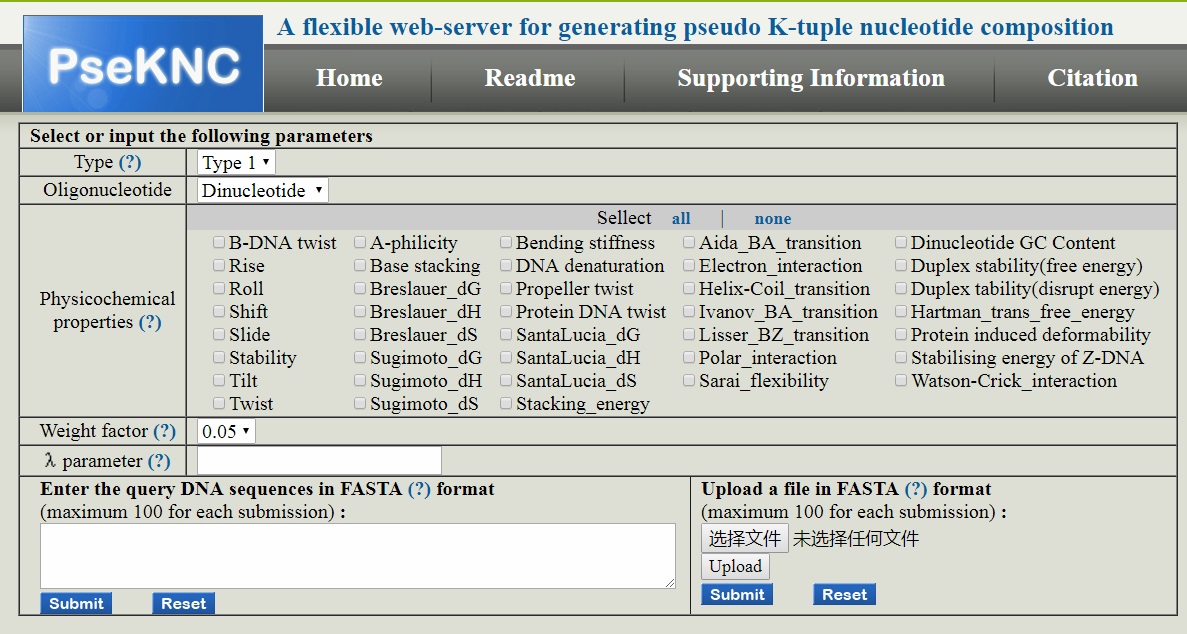 |
PseKNC-General (the general form of pseudo k-tuple nucleotide composition), allows for fast and accurate computation of all the widely used nucleotide structural and physicochemical properties of both DNA and RNA sequences. PseKNC-General can generate several modes of pseudo nucleotide compositions, including conventional k-tuple nucleotide compositions, Moreau–Broto autocorrelation coefficient, Moran autocorrelation coefficient, Geary autocorrelation coefficient, Type I PseKNC and Type II PseKNC. In every mode, >100 physicochemical properties are available for choosing. Moreover, it is flexible enough to allow the users to calculate PseKNC with user-defined properties. The package can be run on Linux, Mac and Windows systems and also provides a graphical user interface. |